Creating AI-generated images with a few words is cool, but have you ever turned text into music? This is exactly what you'll be able to do in the future with a tool called MusicLM.
Google recently published a paper in which they describe a model used for generating high-fidelity music from text descriptions. Following the release of Midjourney and ChatGPT, it may not come as a surprise that artificial intelligence can be used to generate music. Who knows what other types of interesting AI-powered tools we'll see pop up in the future.
The researchers who work on MusicLM note that the recent developments in text-to-image generation served as an inspiration for this model. However, it still remains a big challenge to turn a single text prompt into a rich audio sequence.
The challenge in this field is partly the reason why MusicLM is still not made available to the public. There is also no indication of when we might see a public release for it. For now, you can check out examples of what this AI tool is able to do.
Creating Music with Detailed Text Prompts
The first thing you'll notice when you navigate to the GitHub page for MusicLM is examples of music generated from rich captions. These are 30-second clips that showcase how the model can create music when given a detailed description.
The very first piece of music that you'll hear is supposed to represent the main soundtrack of an arcade game. I didn't expect too much from MusicLM, especially in this phase of its development. And boy was I wrong. I can imagine playing old 2D platformer games to this music.
There are in total ten music clips that you can listen to that were generated from rich captions. They vary in genre, ranging from reggae to techno.
Some of these tracks contain vocals, but they're mostly inaudible. In most cases, the lyrics don't contain actual words. But one can hope that this will be greatly improved in the future.
The thing is that this model will generate a piece of music based on the text prompt. It was trained on a large dataset of music. So, if you ask it to generate a hip-hop or R&B song, it will do it but it won't know how to put syllables together to make them have meaning.
There is still the option to create only an instrumental track and then use a text-to-speech AI tool to generate the vocals. However, it will be amazing if one text-to-music tool can do all of this with one prompt that contains both the description of the instrumental track and the lyrics.
How Is a Text-to-Music AI Model Trained?
Researchers that published the paper on MusicLM explain that the model was trained on a large dataset of unlabeled music. The examples in this dataset were prepared by expert musicians. According to the researchers at Google, the entire dataset will be released to the public at some point in the future to support further research.
MusicLM is trained by leveraging a hierarchy of coarse-to-fine audio discrete units, which are referred to as tokens. The AI tool is significant because it was able to generate sequences of tokens that are very different from the sequences in the dataset it was trained on.
The result of the training is a model that can generate high-quality music at 24 kHz which can last up to several minutes per track and adheres to any given text prompt.
Although the dataset is large enough for the model to learn how to generate music in virtually any genre and recognize various melodies, it's still limited in a sense. There is no doubt that the dataset can be increased, which would in turn make MusicLM even more capable of delivering high-quality music.
Generate Music with a Sequence of Text Prompts
This is perhaps the most brilliant thing I've seen MusicLM do. There is a section with examples of the results the model generated called Story Mode. This basically refers to a sequence of text prompts. You can give the model several prompts together and specify the duration of each entry in the sequence to create a full track.
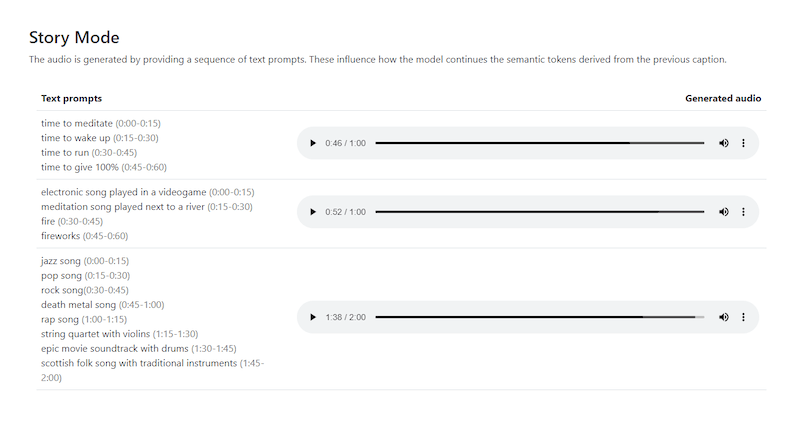
MusicLM truly shines here. Not due to the fact that it gives some type of extraordinary results but because it shows its potential. Once the model is developed enough, people will be able to experiment with different sequences to create full songs.
Each entry in the sequence apart from the initial one has an impact on how the model will continue the semantic tokens it derives from the previous caption. It's essentially a new way to do music layering.
The power of this concept will be fully understood only when a large number of people are able to let their imagination run wild and experiment with MusicLM.
Melody Conditioning with MusicLM
Another powerful feature of MusicLM is its ability to follow a melody that you provide. It's amazing how much thought needs to go into creating something like this. The researchers at Google have to be really innovative in order to create a model with various useful capabilities.
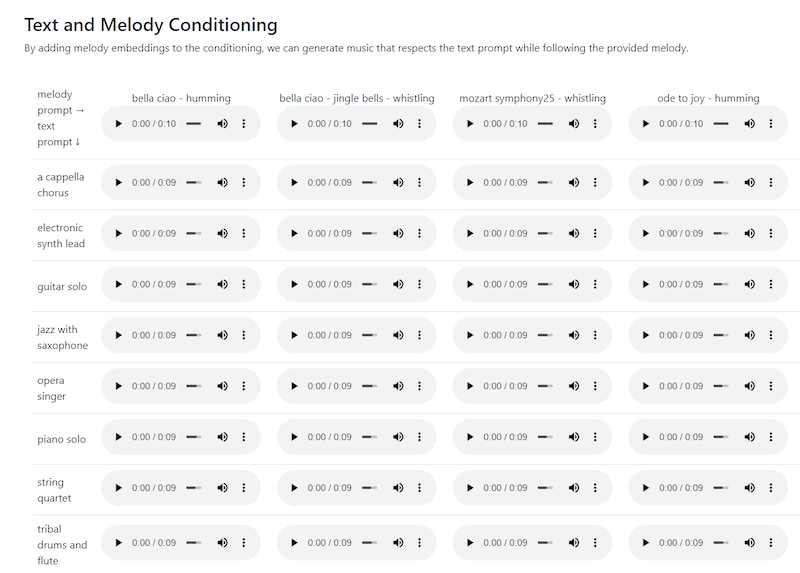
As seen from the examples provided by Google, the model is capable of generating music from the text prompt you give it while also following a specific melody. This is a feature that can be extremely important because it's often difficult to describe a melody with words.
This is where melody conditioning comes into play. You provide the model with a certain melody and then give a text prompt. This basically allows you to generate a music sequence of any type of instrument or vocal that follows a specific melody.
Will You Be Able to Turn Images into Music with AI?
This is not something that you'll be able to do in the near future unless further progress is made in this field, but MusicLM does offer something similar. Granted, you won't directly turn images into music. But you will be able to turn a description of a painting into a song.
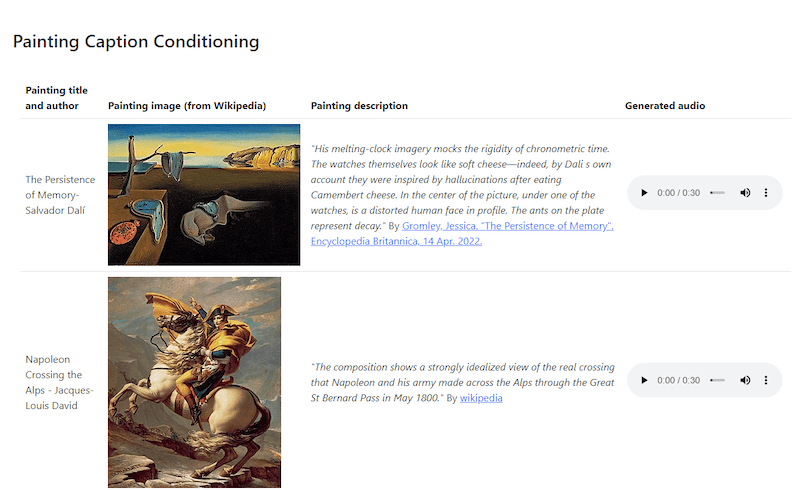
There are several examples that show what happens when you give MusicLM a description of a painting as a text prompt. The results are hard to describe. At least in the examples provided, the model was able to generate what I would describe as background music to some of the most recognizable paintings in the world.
One Model and a Lot of Diversity
If a model like MusicLM would generate one result for each specific prompt, it would still be interesting but not nearly as impressive. Thankfully, this is not something you should expect from this AI-powered tool.
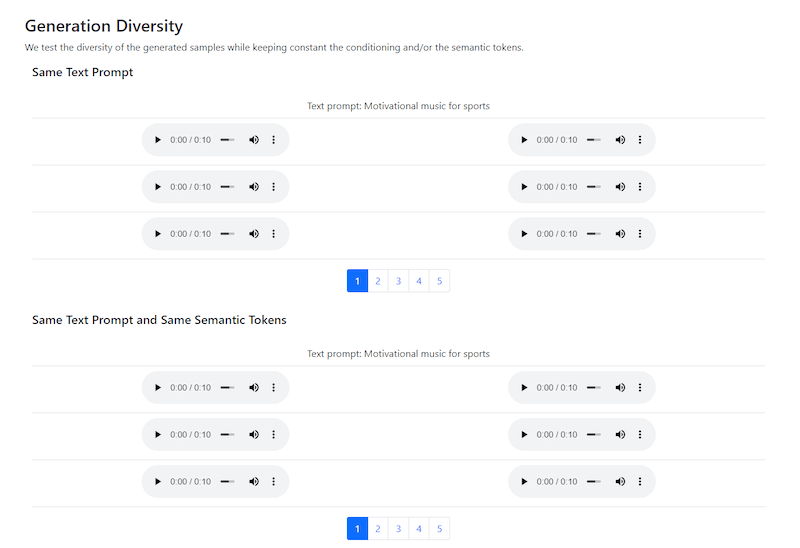
MusicLM offers a lot of diversity, regardless of whether the text prompt is simple or complex. As shown in the examples, a simple prompt like "motivational music for sports" can generate different results.
This is an important feature because if the model would be released to the general public, you'd expect many people to enter the same prompts. You don't want countless users getting the same results, which is why diversity is of the utmost importance.
Final Thoughts
If there is one thing I can take away from taking a deep dive into MusicLM, it's that artificial intelligence will change the world in more ways than I've previously thought. And I mean this in the best way possible.
It's hard for me to imagine what type of AI-powered tools will have only five years from now, let alone in a decade or two. If models like MusicLM are any indication, I believe that the possibilities are endless.
I truly hope that MusicLM or any other similar model will be released to the general public soon so that people can interact with this new type of technology.