I'm very excited to talk about ModelScope today. If you're not familiar with it, you'll discover an amazing tool that you'll likely find yourself experimenting with for a long time. ModelScope is the first truly open-source text-to-video AI model.
This model was released to the public on March 19. It's really new. What's surprising to me is that at the time of writing this article, I haven't seen many people talking about it. The ModelScope team managed to achieve something truly groundbreaking.
If you've been around the early days of text-to-image AI generation, the output you get from ModelScope will be somewhat similar to that. In case you're relatively new to the AI space, you shouldn't expect videos with a quality similar to Midjourney v5. It will take some time before text-to-video AI tools get to that level.
In my opinion, the quality is great for now considering what the model is capable of. You can literally type in just about any text prompt and it will generate a video of it. ModelScope is undoubtedly pushing us in the right direction for this category of AI content generation.
What Is ModelScope?
On 3 November 2022, Alibaba Cloud announced that it would be launching an open-source Model-as-a-Service platform called ModelScope. The MaaS platform would contain hundreds of AI models that would be available for researchers and developers across the globe to experiment with.
Some of these models are pre-trained, like the text-to-video tool. To make this article easier to read, I will refer to this model as ModelScope here since it's the biggest breakthrough to come out of this whole platform.
You can find more information about the model on the official ModelScope website. While there is some English content on the website, most of it is in Chinese. After all, it serves as the site for a project led by Chinese developers, researchers, and scientists.
The AI technology they developed is based on a multi-stage text-to-video generation diffusion model. Input is currently supported only in the English language.
According to the information on the ModelScope website, the diffusion model adopts the Unet3D structure. Video generation is made possible with an iterative denoising process from the pure Gaussian noise video. I don't like to get too technical in my articles because my main goal is to get people to easily understand and use AI tools, so we'll just skip to that part.
How to Generate Videos with Text?
The ModelScope text-to-video model is incredibly easy to use. It was launched on Hugging Face and you can start using it there. It's completely free, but it may take a few minutes to generate a video depending on how many people are waiting in the queue.
The interface is as simple as it gets. You have a field where you can enter a text prompt and when you're done doing that, you click on the "Generate video" button to get the output. It took me between 4-5 minutes on average to generate a video using this model.
You may not be able to start the video generation process on your first few attempts. This happens because a lot of people are using the model at the same time. In this case, you should continue pressing the "Generate video" button until your prompt goes through.
Here's an example of a prompt I wrote for the ModelScope text-to-video model. This is what it looks like when you enter a prompt.
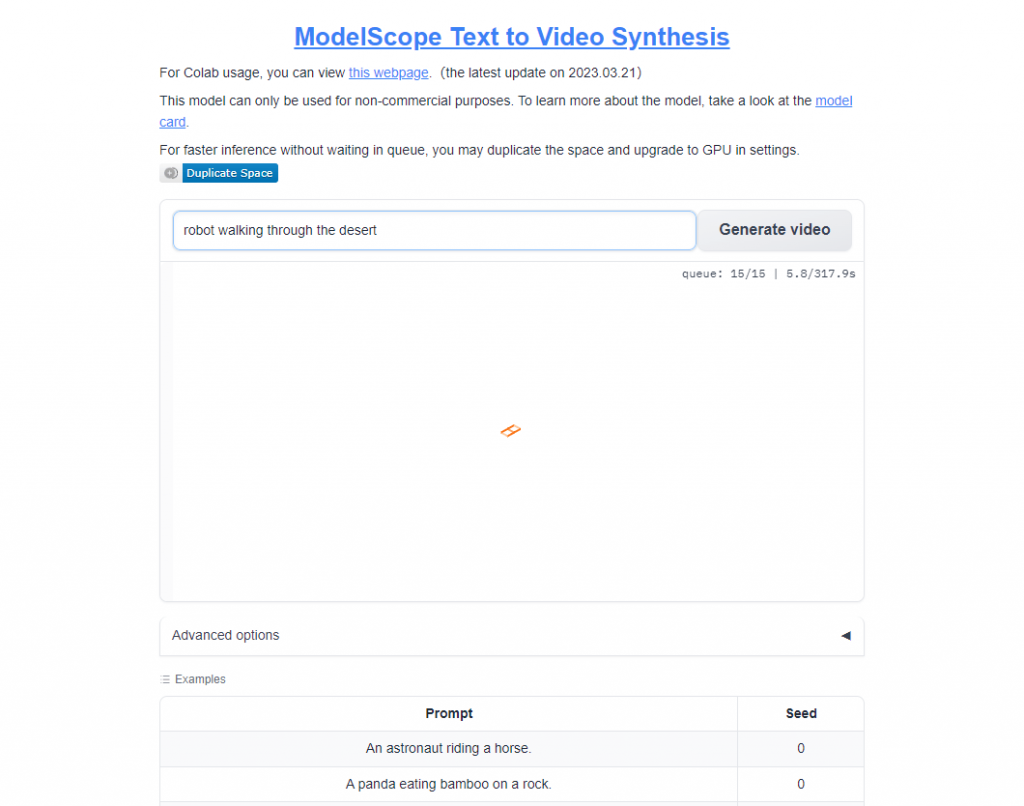
You see what position in the queue you hold and are given a rough estimate of how long it would take for the video to be generated. As you can see from the image above, I gave the model instructions to generate a video of a robot walking through the desert. Here's the generated output.
All videos generated by this model are currently two seconds long. It might not seem much, but the fact that this is possible now means that we'll get much longer and better animations soon.
There are some obvious flaws in this model for now. One thing that people are complaining about is that the vast majority of videos come with a Shutterstock watermark. My opinion is that this will get fixed very quickly, as the technology improves and more data is given to the model.
There are some limitations to this text-to-video AI tool, and they're clearly laid out. For instance, there are some deviations in the output related to the distribution of the training data. Nearly all of the data this model was trained on comes from public data sets like Webvid.
The ModelScope text-to-video AI is unable to generate clear text. It also can't generate output that has a TV or film quality. Another significant limitation is that the model isn't too good at generating videos for complex prompts. If you're using it now, it's best to keep things simple. Don't write a prompt that's a hundred words long. Instead, try to describe what you want to be generated in a single sentence.
There are so many things that I instructed this text-to-video AI model to generate so far, and there is no doubt that I'll keep using this cool tool for a while. I mean, there's literally nothing like it. Here's a video that I generated when I wrote "Batman and a cactus dancing" as a prompt.
I love coming up with random prompts and then seeing how AI will generate them. This video with Batman is so good that I would really like it if it was a few minutes long. Oh well, I guess we'll get there soon enough.
You can also find several examples of what other people generated with this text-to-video tool on the ModelScope website. Here are some examples.

Imagine what YouTube content will be like when a model like this is able to generate videos that are at least a few minutes long. If this type of technology improves drastically in a relatively short amount of time, I think it will have more of an impact on content than Midjourney. Of course, this is just a guess. Nobody knows what will happen next, especially in a space that moves as fast as AI.
What's Next for Text to Video AI?
The output generated by this text-to-video model may seem modest to some, but it's a giant leap forward in generative AI technology. The pace at which artificial intelligence tools evolve is unlike anything we've seen before. This leads me to believe that it won't be long before we see some major improvements here.
One thing I'm especially looking forward to is seeing the different use cases people find for this technology. Of course, I have no doubt that people will use this a lot for entertainment purposes. I've already seen people on Reddit talking about how they want to create endless Simpsons content through a combination of ChatGPT and the ModelScope text-to-video AI technology. I'm looking forward to it.
All in all, this is yet another super exciting development in the AI world. I can't wait to see what's next.